Home
Fundamentals
Research Data Management
FAIR Data Principles
Metadata
Ontologies
Data Sharing
Data Publications
Data Management Plan
Version Control & Git
Public Data Repositories
Persistent Identifiers
Electronic Lab Notebooks (ELN)
DataPLANT Implementations
Annotated Research Context
ARC specification
ARC Commander
Swate
MetadataQuiz
DataHUB
DataPLAN
Ontology Service Landscape
ARC Commander Manual
Setup
Git Installation
ARC Commander Installation
Windows
MacOS
Linux
ARC Commander DataHUB Access
Before we start
Central Functions
Initialize
Clone
Connect
Synchronize
Configure
Branch
ISA Metadata Functions
ISA Metadata
Investigation
Study
Assay
Update
Export
ARCitect Manual
Installation - Windows
Installation - macOS
Installation - Linux
QuickStart
QuickStart - Videos
ARCmanager Manual
What is the ARCmanager?
How to use the ARCmanager
Swate Manual
QuickStart
QuickStart - Videos
Annotation tables
Building blocks
Building Block Types
Adding a Building Block
Filling cells with ontology terms
Advanced Term Search
File Picker
Templates
Contribute Templates
ISA-JSON
DataHUB Manual
Overview
User Settings
Generate a Personal Access Token (PAT)
Projects Panel
ARC Panel
Forks
Working with files
ARC Settings
ARC Wiki
Groups Panel
Create a new user group
CQC Pipelines & validation
Find and use ARC validation packages
Data publications
Passing Continuous Quality Control
Submitting ARCs with ARChigator
Track publication status
Use your DOIs
Guides
ARC User Journey
Create your ARC
ARCitect QuickStart
ARCitect QuickStart - Videos
ARC Commander QuickStart
ARC Commander QuickStart (Experts)
Annotate Data in your ARC
Annotation Principles
ISA File Types
Best Practices For Data Annotation
Swate QuickStart
Swate QuickStart - Videos
Swate Walk-through
Share your ARC
Register at the DataHUB
DataPLANT account
Invite collaborators to your ARC
Sharing ARCs via the DataHUB
Work with your ARC
Using ARCs with Galaxy
Computational Workflows
CWL Introduction
CWL runner installation
CWL Examples
CWL Metadata
Recommended ARC practices
Syncing recommendation
Keep files from syncing to the DataHUB
Managing ARCs across locations
Working with large data files
Adding external data to the ARC
ARCs in Enabling Platforms
Publication to ARC
Troubleshooting
Git Troubleshooting & Tips
Contribute
Swate Templates
Knowledge Base
Teaching Materials
Events 2023
Nov: CEPLAS PhD Module
Oct: CSCS CEPLAS Start Your ARC
Sept: MibiNet CEPLAS Start Your ARC
July: RPTU Summer School on RDM
July: Data Steward Circle
May: CEPLAS Start Your ARC Series
Start Your ARC Series - Videos
Events 2024
TRR175 Becoming FAIR
CEPLAS ARC Trainings – Spring 2024
MibiNet CEPLAS DataPLANT Tool-Workshops
TRR175 Tutzing Retreat
Frequently Asked Questions
last updated at 2024-04-26
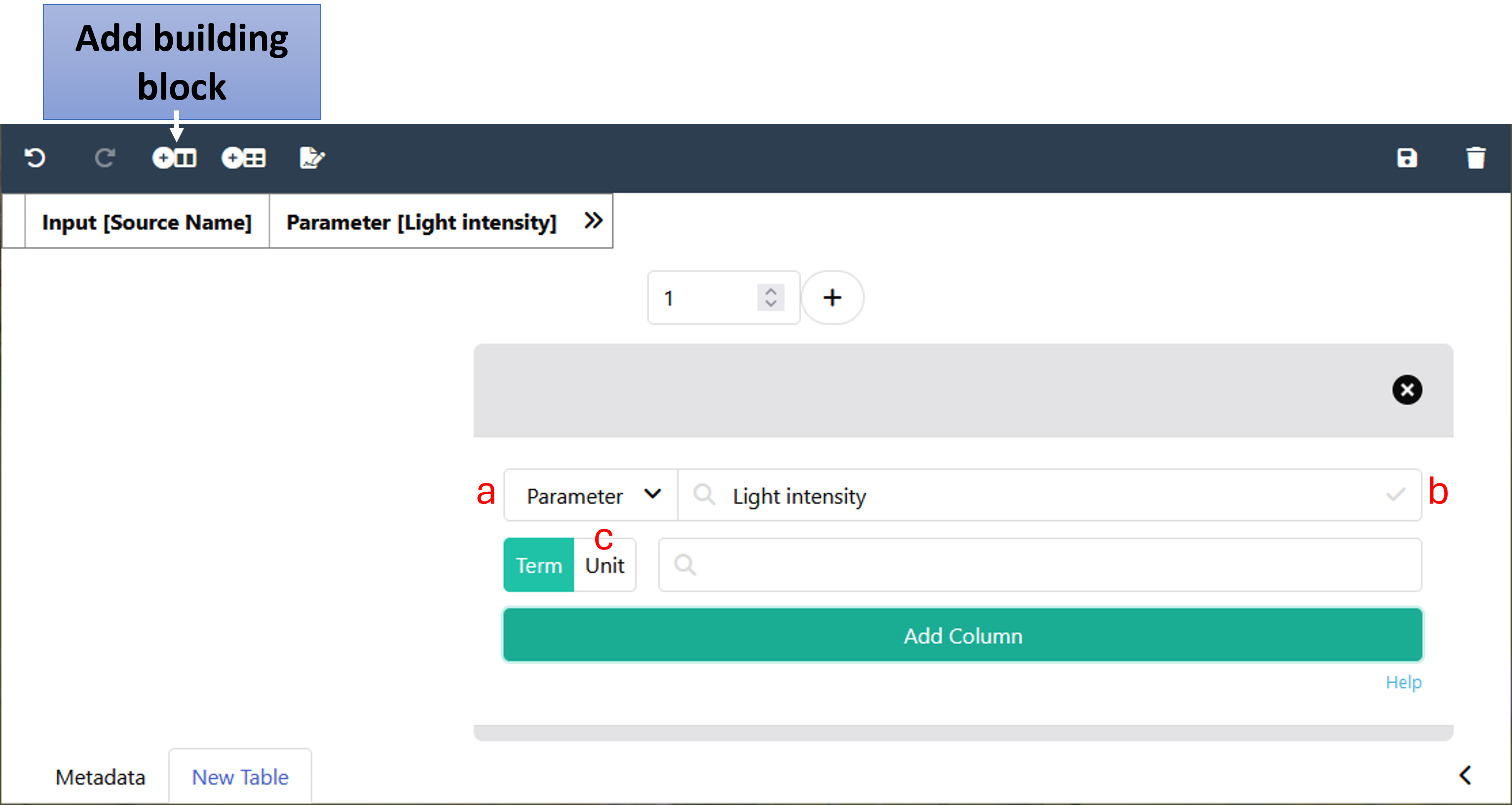
- Click on "Add building block" in the top bar or in the sidebar.
- Choose the type of building block you want to add ( a ). For more information on building block types, click here.
- If you chose a descriptive building block type, use search field ( b ) to search for an ontology term. This term together with your building block type describes your workflow. If you want to add a building block with a unit, activate the unit box ( c ) and use the search field to look for a fitting unit term.
- If you cannot find a fitting term, you can write an issue to request an ontology term here OR use free text input.
- Click Add column to insert the building block into an existing Annotation Table. The new building block will be added to the right side of the table. To change the position you can right-click into any cell (except the header) of the column you want to move and select "Move Column".
- Any Input or Output building block will only add a single column, any descriptive building block will add three columns or four columns if it is created with a unit. Only the main column will be visible by default, all other reference columns will be hidden.
- 👀 You can expand the hidden columns with the two arrows (>>) in the header of the first column.
DataPLANT Support
Besides these technical solutions, DataPLANT supports you with community-engaged data stewardship. For further assistance, feel free to reach out via our
helpdesk
or by contacting us
directly
.